RSS („Really Simple Syndication“) yra standartizuotas formatas, kurį internetiniai leidėjai naudoja sindikuoti jų turinį kitoms svetainėms ir paslaugoms. An RSS dokumentas, taip pat žinomas kaip a maitinti, yra XML dokumentas turinį, kurį leidėjas nori platinti.
RSS kanalai yra prieinami beveik visose interneto naujienų svetainėse ir tinklaraščiuose, kuriuose skaitytojai gali nuolat atnaujinti savo turinį. Juos taip pat galima rasti ne tekstinėmis svetainėmis pvz., „YouTube“, kur galite naudoti „YouTube“ kanalo kanalą apie naujausius vaizdo įrašus.
Skambinamos programos, leidžiančios pasiekti šiuos kanalus ir skaityti bei rodyti jų turinį RSS skaitytojai. „JavaScript“ programoje galite sukurti paprastą RSS skaitymo programą. Šioje instrukcijoje pamatysime, kaip.
RSS informacijos santraukos struktūra
RSS kanalas turi šakninį elementą vadinamas , panašus į žyma, esanti HTML dokumentuose. Viduje žyma, yra a elementas, panašus HTML, tai apima daug elementų turinčius platinamą svetainės turinį.
Paprastai pašaruose yra pašarų Pagrindinė informacija pvz., svetainės pavadinimas, URL ir aprašymas individualūs atnaujinti įrašai, straipsniai ar kitas turinys svetainėje. Ši informacija yra </code>, <code><link></code>, ir <code><description></code> elementus.</p> <p>Kai šios žymės yra <strong>viduje <code><channel></code></strong>, jie turi svetainės pavadinimą, URL ir aprašymą. Kai jie yra <strong>viduje <code><item></code></strong> kad <strong>turi informaciją apie atnaujintus įrašus</strong>, jie atstovauja tą pačią informaciją, kaip ir anksčiau, bet kiekvienos atskiros informacijos <code><item></code> atstovauti.</p> <p>Taip pat yra keletas <strong>neprivalomi elementai</strong> kuri gali būti teikiama RSS kanale, teikiant papildomą informaciją, pvz., vaizdus ar autorių teises, apie platinamą turinį. Apie juos galite sužinoti šiame <strong>RSS 2.0 specifikacija</strong> cyber.harvard.edu.</p> <p>Štai pavyzdys, kaip <strong>Svetainės RSS kanalas</strong> gali atrodyti:</p> <pre name="code"> <rss version="2.0"> <channel> <title>Hongkiat https://www.hongkiat.com/ Dizaino patarimai, pamoka ir įkvėpimailt-mumsVizualizuokite bet kurią CSS stilių lentelę su CSS statistikaAr kada nors susimąstėte, kiek CSS taisyklių yra stiliaus lape? Arba kada nors norėjote pamatyti… 17/05/2017 https://www.hongkiat.com/blog/css-stylesheet-with-css-stats/ „Amazon Echo Show“ - naujausias „Alexa“ valdomas „Smart Device“„Amazon“ nepažįsta protingų namų sistemų koncepcijos su integruotu skaitmeniniu asistentu. Galų gale,… 17/05/2017 https://www.hongkiat.com/blog/alexa-device-amazon-echo-show/
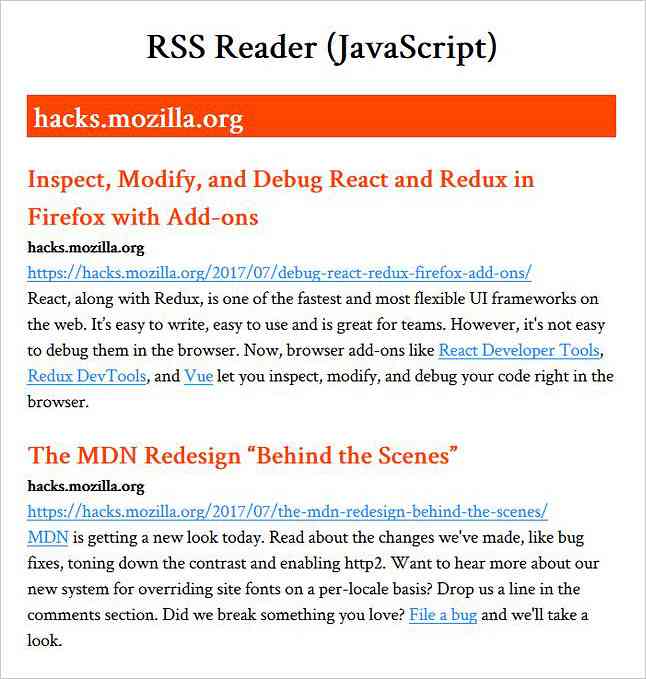
Gaunamas pašaras
Mums reikia pareikalauti pašarų su mūsų RSS skaitytuvo programa. Svetainėje gali būti RSS kanalo URL rasti viduje žyma naudojant application / rss + xml tipas. Pavyzdžiui, „Hongkiat.com“ rasite šią RSS informacijos santrauką.
Pirma, pažiūrėkime, kaip gauti svetainės URL adresą naudojant „JavaScript“.
The atsiimti () metodas yra pasaulinis metodas asinchroniškai atsiunčia šaltinį. Jis nurodo šaltinio URL kaip argumentą (mūsų kodo svetainės URL). Tai grąžina a Pažadas todėl, kai metodas sėkmingai atsiunčia svetainę (t. y Pažadas įvykdyta), pirmoji funkcija viduje tada () pareiškimas tvarko atsiųstą atsakymą (res virš kodo).
Tada gautas atsakymas visiškai perskaityti į teksto eilutę naudojant tekstas () metodas. Šis tekstas reiškia HTML įkeltos svetainės tekstas. Kaip atsiimti (), tekstas () taip pat grąžina a Pažadas objektą. Taigi, kai jis sėkmingai sukuria atsakymo tekstą iš atsakymo srauto, tada () tvarkys šį atsakymo tekstą (htmlText virš kodo).
Kai bus prieinamas HTML svetainės tekstas, mes naudojame DOMParser API į išanalizuoti jį į DOM dokumentą. DOMParser analizuoja XML / HTML teksto eilutę į DOM dokumentą. Jo metodas, parseFromString (), mano du argumentai: tekstą, kurį reikia išanalizuoti ir turinio tipas.
Tada iš sukurto DOM dokumento mes Surask href atitinkamos vertės žyma naudojant querySelector () metodas, kad gautumėte pašarų URL.
Pašarų analizavimas ir rodymas
Kai gausime svetainės informacijos URL, turime atsiųskite ir perskaitykite RSS dokumentą rasti tame URL.
Tokiu pat būdu, kaip mes parsisiuntome ir analizavome svetainę, dabar mes gauti ir analizuoti XML kanalą į DOM dokumentą. Norėdami tai pasiekti, mes naudojame „text / xml“ turinio tipas parseFromString () metodas.
Išnagrinėtoje dokumente mes pasirinkite visus elementus naudojant querySelectorAll metodas ir per kiekvieną.